引言
剩下的课程讲的是如何运用一个大数据集(百万上亿),帮助我们提高算法的效果。以及一个照片ORC问题的完整介绍。
Tips:剩下两周竟然没有编程作业。
何时需要大数据集
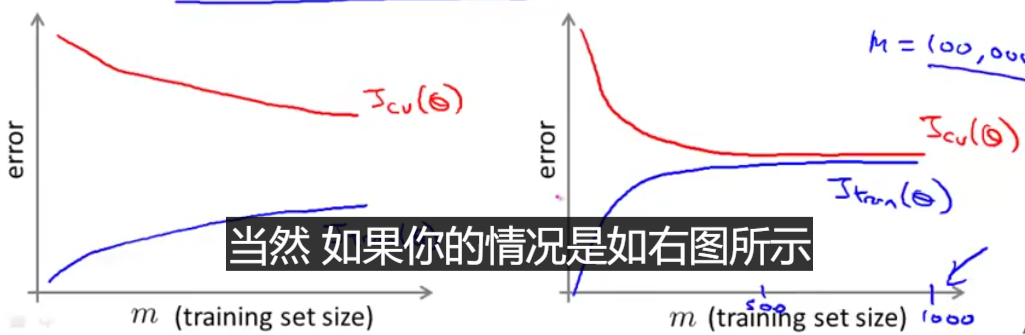
首先你有一个模型,然后画一个误差-数据集大小的图出来。肯定会类似于上面两个中的一个。如果是左边这种,那么增加数据集大小肯定是好的,右边这种明显是高偏差,需要添加更多的特征,而不是增加数据集大小。
随机梯度下降(Stochastic Gradient Descent, SGD)
原来的梯度下降,当数据量过大的时候,梯度的计算量就会特别的大。所以发明了一种新的算法,叫随机梯度下降,在计算梯度的时候,一次只考虑一个样本,也就是将一个样本的梯度作为整体的梯度。
以下是随机梯度下降的步骤:
- 随机打乱训练样本。
- 重复以下步骤:(1-10次即可)
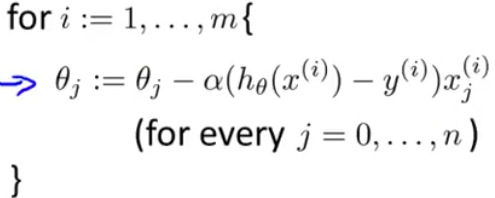
小批量梯度下降(Mini-Batch Gradient Descent)
其实是随机梯度下降法的一个延伸。小批量梯度下降的思想就是利用一小部分训练样本的总梯度代替所有样本的总梯度。
简单对比一下就是:
- (批量)梯度下降:用所有的样本的梯度。
- 随机梯度下降:用一个样本的梯度。
- 小批量梯度下降:用2-100个样本的梯度。
只有在,梯度求和的时候,有一个好的向量化实现时,小批量梯度下降的速度可能会比随机梯度下降还快。
检查收敛性
- 批量梯度下降:画出代价函数
J随着迭代次数增加而变化的曲线。 - 随机梯度下降:先定义一个函数

- 当梯度算法在扫描训练集里面的样本的时候,在更新梯度之前,计算这个
cost函数的值。 - 在每1000次迭代中,计算最后1000个样本的
cost函数值和的均值。
- 当梯度算法在扫描训练集里面的样本的时候,在更新梯度之前,计算这个
随机梯度下降最后会收敛到全局最小值附近,会在那周围晃悠,最后的值是一个接近于全局最优的值。如果你想得到更好的值,可以尝试随着迭代减小学习率。
Photo OCR(Photo Optical Character Recognition)
说大白话就是,识别照片中的文字。运行一个照片ORC程序,大致分为以下几步:
- 找到带有文字的区域。
- 将文字按最小单元(中文是字,英文是字母)分隔开。
- 对每一个分隔的单元进行分类。
- 高级一点的,还可能包括拼写纠正。
框出带有文字区域
首先是第一步,从一张图片里面挑出带有文字的部分,像下面这样:

那么是如何实现呢?(其实我对后面的第三部比较了解,反而是前两步我比较困惑)
在这里以行人识别为例:

要从一张图片中,识别出每一个人来,我们分为以下几步:
- 我们首先准备一堆
82*36大小的图片,分别是带有行人的和不带行人的,类似于下面(尽量让人填满整个照片):
- 用一个算法模型,对图片进行分类训练,代表了图片中有行人,或者没有行人。
- 然后用一个
82*36大小的框,从你要识别的原图片中截取一块出来,放到刚刚训练的算法里面进行识别:
- 然后把绿色的框框往右挪一点(右挪的长度称为步长),再取一点出来进行识别:

- 直到图片最右下角取完,然后再取一个更大的框,重复上面两步(注意!取出来的更大的图片,需要变换成
82*36的大小,也就是训练时候用的大小):
回到刚刚文字识别的问题中,那么要识别文字,还是先按照上面的做法,对每一个识别出来的区域,在一个黑白图上标为白色:

然后将白色的区域都展开成一个更大一点点的方块:

将连在一起的方块框起来,然后根据长宽比(正常的文字一般会长一点),筛选出文字。
文字分割
对于文字分割,还是类似于上面的,不过把训练样本换成这样:
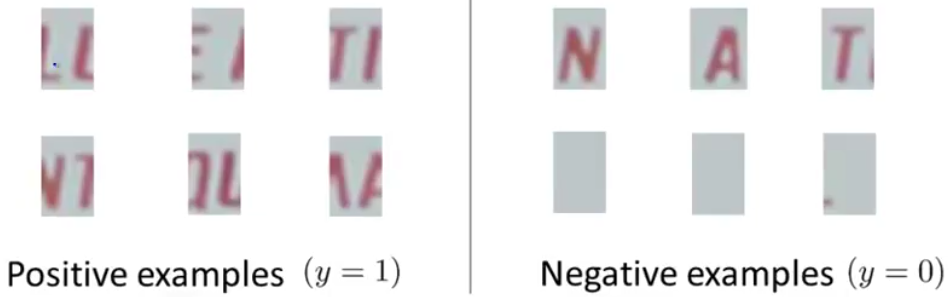
把这种类似于文字中间的部分给挑出来,作为正样本,单独的每一个作为负样本。
后面的就同上了。但是在这里面,我觉得有一点小细节,我自己脑补的,在进行这样一个滑窗识别的时候,小步长可能会导致对同一对字符的分割线会有很多个:

上图中,红框、绿框、黄框都有可能识别为分割线,当步长更小的时候,会有更多的框识别为1。但是分割线只能有一个,所以我觉得,可以在识别出来的这些框里面取一个中间值。(纯属自己脑补的问题)
人工造假创造数据
当你遇到一个问题,希望用机器学习来解决,那么肯定会希望能使用一种低偏差模型,然后使用大量的数据去训练模型。但是获取大量的数据并不容易,有没有什么办法能相对简单的获取大量的数据呢?
这就是人造数据,对于文字ORC问题,可以将各种字库里面的字贴在一个随机的背景中,然后再加上一些随机的放大扭曲旋转之类的。
还有一种办法就是,利用你已经有的数据,进行扭曲旋转或者变形之类的,类似下图:
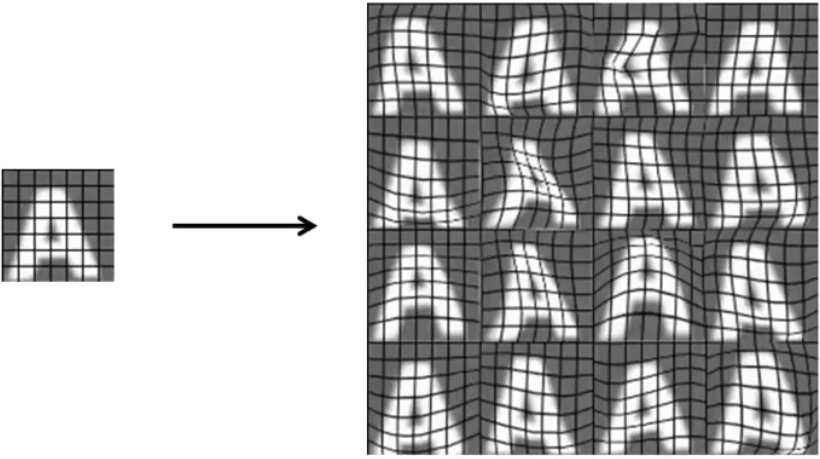
对于音频识别,我们可以用一段干净的人声,然后在其中添加上不同的背景噪音,这样就可以生成很多个样本。
上限分析
当你的系统被分为了几个模块的时候,分析每个模块的提升对整个系统的提升有多少就显得很必要。
还是以文字ORC问题为例,我们有文字检测->文字分割->文字识别,一共三个部分。假设正常工作的时候,系统最后的准确率有72%。
然后首先将文字检测部分用100%正确的内容替换掉,也就是人工给与文字分隔部分完全正确的识别。这个时候系统最后正确率上升到89%。
同理将完全正确的文字分割给文字识别,这个时候准确率上升到90%。完全正确的文字识别当然是100%啦。接下来就有下表:
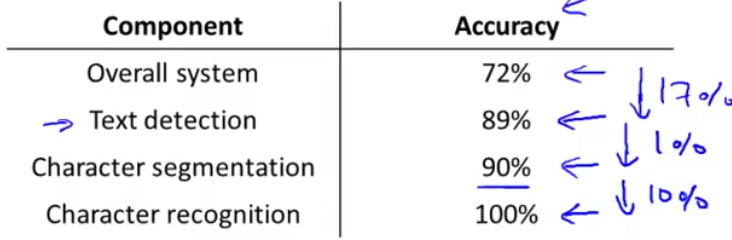
从表中就可以很明显的看出来,提升文字检测和文字识别两个部分对算法的提升比较大,而文字分割部分对算法的提升却很小。
后记
完结撒花!!!!!最后一周确实让我大开眼界,了解了很多以前没了解过的,特别是这个上限分析。
结束了Coursera的课程,这个课程相对比较基础,数学涉及很少。之后就要进入正式的课程了——机器学习基石和机器学习技法。