引言
异常检测
什么叫异常检测
好比你生产了一堆飞机引擎,并且有一些参数用作引擎是否合格的参考。那么这些参数在一个空间内肯定有一个分布,分布肯定就会有一个比较密集的区域,那么越靠近这个密集区域,合格的几率肯定就越大,越远肯定就越可能是坏的。
高斯分布参数估计
如果你有一个数据集,而且你估计他服从高斯分布,那么数据集服从的高斯分布的两个参数分别可以这么算:
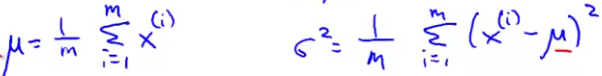
密度估计
根据自然事物都基本服从高斯分布的特点,我们将拥有的m个样本的n个特征都当做服从高斯分布,然后假设他们互相独立(即使不独立,在使用的时候也没有太大的影响),我们就计算每个样本的所有特征概率之积:
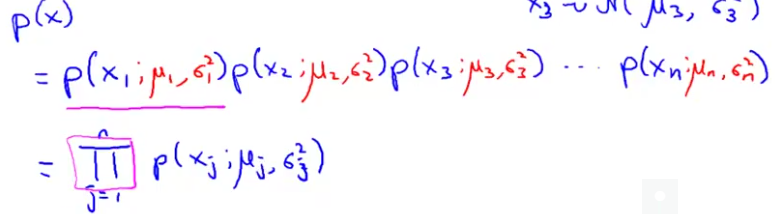
粉色框框框住的符号表示连乘的意思。
异常检测算法
讲了那么多前置,才讲到异常检测算法。
- 首先选择你的特征。
- 估计每个特征的高斯分布参数。
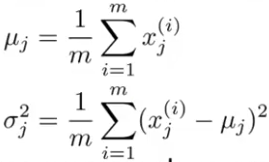
- 计算新特征的密度估计:
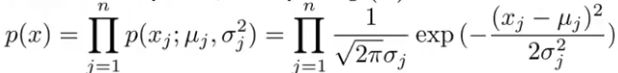
- 如果这个值小于某个设定值,就可以判定为异常点。
评价异常检测算法的方法
之前讲过,评价不同模型之间的好坏,都是一种数值评价法,就是能有一个确切的数值,来评判不同模型之间的优劣。评价异常检测也是一样,要用数字说话,而不是感觉。
要用数字说话,就免不了需要带标签得数据。然后定义训练集,训练集是不需要标签的,即使有一些负例在里面也没关系。接着需要定义交叉训练集和验证集,这是需要带标签得,毕竟需要验证。
假设我们有10000个好的引擎数据(即使里面有一些坏的也没关系,只要绝大部分是好的就行),20个坏的引擎数据。然后分为:
- 训练集:6000个好的引擎
- 交叉验证集:2000个好的引擎,10个坏的引擎
- 验证集:2000个好的引擎,10个坏的引擎
因为这个是一个偏斜类(分类里面讲过,样本里面一类比另一类的数量大得多),这样肯定不能用正确率来判断。要用F数值,或者别的什么。
异常检测VS有监督学习
异常检测里面需要用到有标签的样本,那么有一个疑问,为什么不用有监督学习呢?
这个问题,就要回到上古时代,咳咳,不是,是样本数量问题。
例如,在进行飞机机翼检测的时候,通常来说,都会有很多好的机翼样本(y=0),而坏的机翼样本少得可怜(y=1)。所以在你的正样本数量很少的时候,就适合用异常检测。
当正负样本数量都很多的时候,还是比较适合用有监督学习。
如何将特征变得有用
有时候,数据并不会看起来像高斯分布:
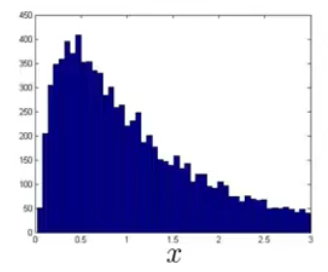
这种时候,就可以使用log(x+1)或者x^(0.5)这样的来变换数据,这样数据就会变得更像高斯分布一点。
多元高斯分布
有时候讨论一维的高斯分布,还是不能很好地检测异常,所以需要联合多个特征,也就是多元高斯分布。
给出多元高斯分布的一个公式:

其中用粉红色圈圈出来的那个符号,在matlab里面是有对应的函数可以直接算出来的:det(Sigma)。
而这个P函数有两个参数,这两个参数会影响多元高斯分布的图形。

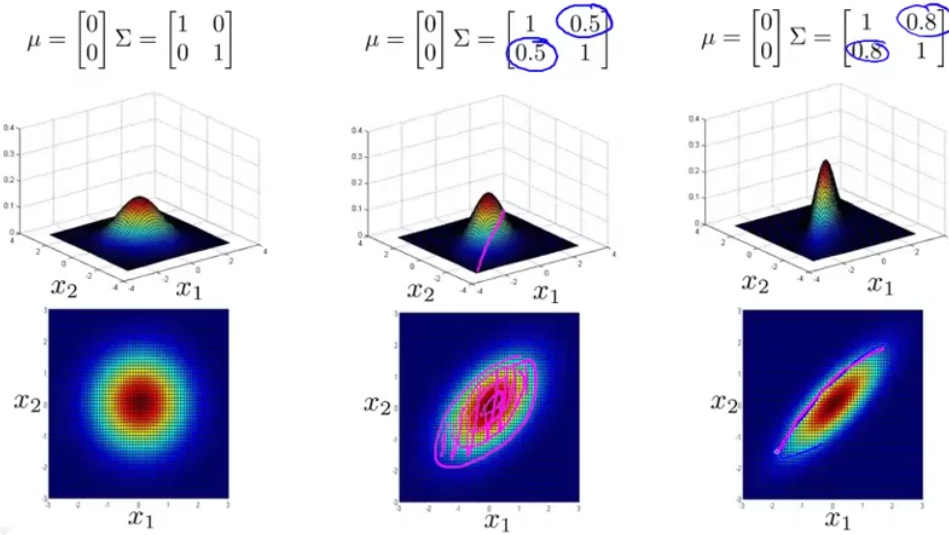
多元高斯分布参数拟合
刚刚说到,函数里面有两个参数,那么这两个参数怎么得到呢?
假设你有一堆数据:
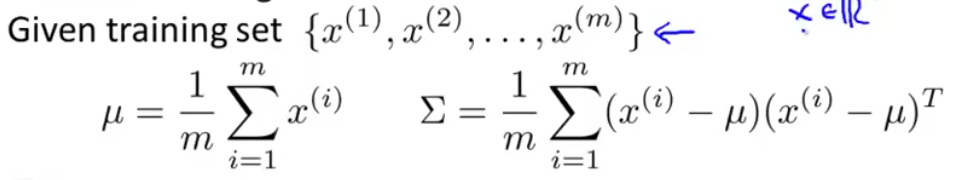
多元高斯分布和原模型
有趣的是,原来的独立高斯概率相乘,其实是多元高斯分布的一种特例,也就是当Σ为对角阵的时候,其分布的等高线只会沿着轴向变换,而不会出现斜着的椭圆:

多元高斯分布VS独立高斯分布
那么两种模型,到底什么时候该用哪一个呢?相较而言,独立高斯分布会更常见一点,而多元高斯分布会少见一点。
以服务器群为例,如果你想检测服务器集群是否工作正常,而且有内存占用量和CPU占用量等特征,如果CPU满载而内存无动于衷,那么这个服务器肯定需要检查一下。
在独立高斯分布中,你就需要对这两个量进行一个关系处理,生成一个新的特征量,比方说CPU占用量除以内存占用量,简而言之就是需要捕捉不正常的特征量组合。但是多元高斯分布你就不需要这样处理。
相比之下,原模型的计算量会小很多,而多元高斯分布会消耗很多计算资源。
其次,独立高斯分布在样本数量小的情况下,也能很好的运行,而多元高斯分布,只有在样本数量大于特征数量的时候才能正常运行(实际中在样本数量大于10倍特征数量的时候才会考虑用多元高斯分布)。
后记
这一周的内容太多了,于是我就把推荐系统拆到了下一篇文章里面啦~(为了科研,学习进度落后了很多,难受的一批)