引言
从零开始搭建一种可灵活调整每层神经元数量、激活函数以及损失函数等参数的神经网络(框架)。
目标
本文的目标在于设计一种,可以用于拟合,也可以用于分类的神经网络。该神经网络可以灵活地调整每一层的神经元数量和各种参数。
本文对于神经网络的基本原理不会详细讲解,只会在适当的地方点一下,如有想学习基础原理的,请另寻他处。
设计思路
设计这种有点像小框架的东西,很需要思路。现有的思路有两种,一种是类似于Keras的,一种是类似于Tensorflow的。
我选了类似于Keras的,将神经网络作为一个实例,往实例里面添加层,在每一层里面设置相应的参数。然后往实例里面加入数据进行训练,就完成了一个模型。
整体架构
整体设计思路采用面向对象的方法,所以首先得有一个神经网络类,还需要一个神经层类。每个类有相应的方法。
神经网络类
神经网络类里面的方法包括如下这些:
- 构造函数。存放一些全局变量。
- 神经层添加函数。用于给神经网络添加神经层。
- 训练函数。控制训练流程。
- 前向传播函数。计算前向传播。
- 反向传播函数。计算反向传播。
- 预测函数。用于预测新的数据。
- 保存模型。
- 加载模型。
神经层类
神经层类的方法包括这些:
- 构造函数。
- 前向计算。
- 计算误差。
- 计算神经元梯度。
- 更新权值。
- 计算激活函数梯度。
通用函数
这里面还包括一些通用函数:
- sigmoid函数。
- sigmoid梯度函数。
- relu函数。
- relu梯度函数。
- softmax函数。
- softmax与交叉熵函数。
- softmax与误差函数。
通用函数
万事开头难,那我们就从简单的开始。
sigmoid函数及其梯度函数
1 | def sigmoid(Z): |
relu函数及其梯度函数
1 | def relu(Z): |
softmax函数及其反向传播相关函数
1 | def softmax(z): |
这里尤其要说明一下这个softmax。
softmax可以作为中间层的激活函数(不推荐),也可以搭配交叉熵最为最后的激活函数进行多分类(强烈推荐)。但是用于分类的时候就有一点迷惑。
为什么要写softmax和softmax与交叉熵两个函数,而没有单独写交叉熵损失函数呢。(因为不好写XD!)其实是没必要写,因为反向传播的时候不单独算交叉熵的误差和梯度(这个确实是因为不好算),而是和softmax一起算,跳过了中间的步骤。公式推导可以看这里。
那又为啥要单独写一个softmax函数呢。因为前向传播分为两种(此处参考了这篇文章):
- 推理预测时的前向传播。因为此时不需要计算loss,也不需要反向传播,就不需要用到softmax, 只用logits就可以做出预测,可以减少计算量(所以用softmax概率化后的得分也是可以的)。
- 训练时的前向传播。此时需要记录中间变量z和a,用于反向传播,所以需要进行softmax计算。
神经层
构造函数
1 | class Layer: |
前向计算
1 | def _forward(self, X, Y): |
计算本层误差
1 | def count_err(self, front_err, Y): |
依据的公式为如下两个,第一个是最后一层的误差:

中间层的误差:
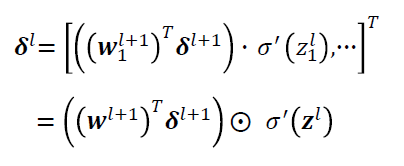
解释一下上面的式子。记每一层输入到神经元的输入记为z,也就是w*x,其中的x为上一层的输出,w为这一层的权值。
先看最后一层,最后一层的误差等于损失函数的梯度乘以这一层激活函数的梯度。
然后对于中间层,这一层的误差等于本层激活函数的梯度乘以(后一层的w乘以后一层的误差)。
如果将损失函数也看做一个神经层,最后一层和损失函数之间的权值w=1,那么损失函数的梯度就可以看做是最后一层的后一层的误差。就可以将上面的汇总成一个。
计算本层权值的梯度
1 | def count_gradient(self, al_1): |
计算权值梯度就是用前一层的a乘以自己这一层的误差。a表示一层神经元经过激活函数后的输出。
更新权值
1 | def update_parameters(self, rate, n): |
本层激活函数的梯度
1 | def act_gradient(self, Z): |
小结
将不同的激活函数、不同的层都集中到一个方法里面,是为了更好的实现面向对象编程,实现方法复用。
神经网络
构造函数
1 | class NeuralNetwork: |
用于存放神经层的。
添加神经层
1 | def add_layer(self, layers_dims, activation='relu'): |
前向传播
1 | def forward(self, X, Y, mission): |
反向传播
1 | def backward(self, out, x, y, rate, mission): |
在这里要特别注意,因为反向传播是从后往前算,所以我在最开始将神经层逆序了,在最后又逆序回来了。然后拟合的损失函数用的平方损失函数,就没有单独拿出来了,有兴趣的同学可以自己改,改成不同的损失函数。
训练
1 | def train(self, x, y, mission, epochs=1000, batch_size=50, learning_rate=0.01, data_rate=0.6, target=None, print_cost=False): |
训练的话就没什么特别需要注意的了,都是老生常谈。只是里面的load_data和load_batch两个函数我没有在这里给出,详情可以看我的github,在最后给出链接。
预测
1 | def predict(self, x, y, mission): |
预测也没什么好说,就是前向传播,然后分了回归和分类两个任务。
保存和加载
1 | def save_model(self, name): |
用的是Python自带的pickle库,还是挺好使的。
总结
中间很多都是一笔带过,其实只是涉及实现的话,我觉得难点在于以下几点:
- 将分类和回归的正反传播结合起来。
- 弄懂神经网络最后一层和损失函数之间该怎么反向传播,特别是分类的时候。Tips:我觉得这里可以将损失函数也理解成一层,但是和最后一层的输出是直连,中间的权值为1。
- 弄懂
softmax和交叉熵怎么一起算反向传播。
后记
更详细更全面的代码,可以看我的github。欢迎Star~